Currently Empty: ₹0.00

LLM
0 Comments
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is an advanced deep learning model trained on massive datasets containing text from books, websites, code repositories, and structured documents. LLMs are designed to understand natural language, generate human-like responses, and perform reasoning across a wide variety of tasks.
LLMs use transformer-based architectures, which allow them to analyze relationships between words and sentences across long contexts. This makes them capable of understanding intent, summarizing content, answering questions, generating code, and even planning multi-step workflows.
In AI Agent Architecture, the LLM acts as the central brain, making decisions, reasoning over retrieved information, and coordinating with tools and memory systems.
Core Capabilities of LLMs
LLMs provide several foundational capabilities that power modern AI systems:
- Natural language understanding and generation
- Context-aware reasoning
- Text summarization and paraphrasing
- Code generation and analysis
- Multilingual communication
- Question answering and knowledge synthesis
These capabilities make LLMs suitable for a wide range of enterprise and consumer applications.
Popular LLM Models and Ecosystem
Popular LLMs include GPT, Claude, LLaMA, and Gemini. These models vary in terms of:
- Training data size
- Reasoning performance
- Cost and latency
- Open-source vs closed-source availability
Open-source models like LLaMA allow on-premise deployment, while cloud-based models provide scalability and ease of integration.
Tokenization in LLMs
Tokenization is the process of breaking text into smaller units called tokens. Tokens may represent words, sub-words, or characters. Efficient tokenization allows LLMs to process large text efficiently while maintaining semantic meaning.
Understanding token limits is crucial for:
- Prompt design
- Cost optimization
- Context window management
Embeddings and Semantic Understanding
Embeddings are numerical vector representations of text that capture semantic meaning. Similar pieces of text have similar embeddings. Embeddings are used extensively in:
- Semantic search
- Recommendation systems
- Clustering and classification
- RAG pipelines
Embeddings enable LLMs to “understand” meaning rather than just keywords.
Prompt Engineering Techniques
Prompt engineering plays a vital role in controlling LLM behavior. Common techniques include:
- Zero-shot prompting
- Few-shot prompting
- Chain-of-thought reasoning
- Role-based prompting
Well-engineered prompts improve response accuracy, reduce ambiguity, and enable complex reasoning.
Fine-Tuning vs Prompt-Based Learning
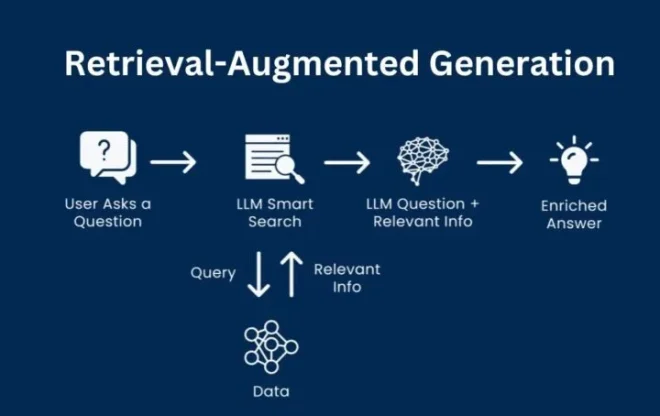
Fine-tuning modifies a model’s internal weights using domain-specific data, while prompt-based learning guides model behavior without retraining. Fine-tuning is costly and static, whereas prompt-based learning combined with RAG provides flexibility and real-time knowledge updates.
LLM APIs and Integration Patterns
LLMs are typically accessed via APIs. These APIs allow:
- Secure authentication
- Rate limiting
- Logging and monitoring
- Version control
APIs make LLMs easy to integrate into applications such as chatbots, automation tools, and data analysis platforms.
LLM Limitations and Challenges
Despite their power, LLMs face challenges such as:
- Hallucinations (fabricated responses)
- Bias in training data
- Limited real-time knowledge
- High computational cost
These limitations are addressed through architectural patterns like RAG, validation layers, and human-in-the-loop systems.
Role of LLMs in AI Agent Architecture
In AI Agent Architecture, LLMs serve as:
- Decision makers
- Reasoning engines
- Natural language interfaces
- Planners for multi-step tasks