Currently Empty: ₹0.00
RAG
0 Comments
What is Retrieval-Augmented Generation (RAG)?
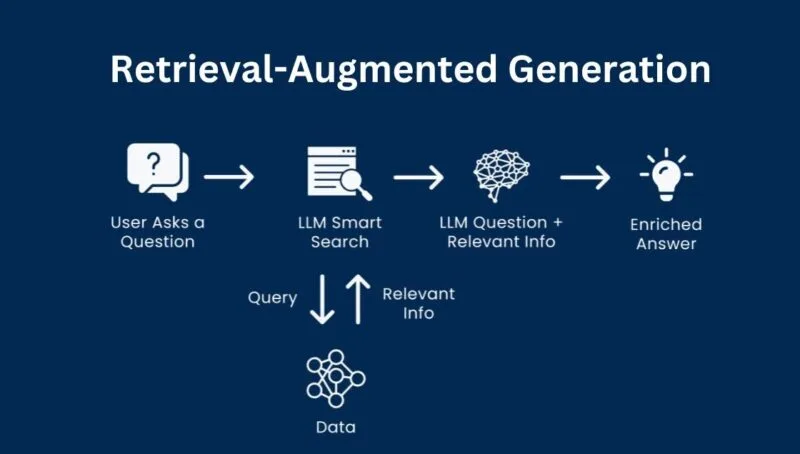
Retrieval-Augmented Generation (RAG) is an AI architecture pattern that combines information retrieval systems with Large Language Models (LLMs) to generate accurate, grounded, and context-aware responses. Instead of relying solely on the model’s internal knowledge, RAG retrieves relevant information from external data sources and provides it to the LLM at inference time.
This approach significantly reduces hallucinations and ensures that AI agents produce fact-based, up-to-date, and domain-specific answers.
Why RAG is Critical for AI Agents
LLMs are trained on static datasets and cannot inherently access private or real-time data. RAG solves this limitation by allowing AI agents to:
- Access proprietary knowledge bases
- Use updated documents without retraining
- Provide traceable and explainable answers
- Scale knowledge across large organizations
RAG transforms AI agents from generic chatbots into trusted enterprise assistants.
RAG Architecture
A typical RAG architecture consists of the following layers:
- Data Source Layer
Documents such as PDFs, Word files, web pages, databases, APIs, and internal systems. - Data Ingestion & Preprocessing
Text is cleaned, chunked, and normalized to ensure optimal retrieval quality. - Embedding Generation
Each chunk is converted into a numerical vector using embedding models. - Vector Storage
Embeddings are stored in vector databases like FAISS, Pinecone, or Chroma. - Retrieval Layer
User queries are converted into embeddings and matched using similarity search. - Generation Layer
Retrieved context is passed to the LLM to generate the final response.
This layered approach ensures both scalability and accuracy.
Document Chunking Strategies
Effective chunking is critical for RAG performance. Common strategies include:
- Fixed-size chunking
- Semantic chunking
- Overlapping chunks
Poor chunking leads to irrelevant retrieval, while optimized chunking improves response quality significantly.
Vector Databases in RAG
Vector databases store and index embeddings for fast similarity search. Popular options include:
- FAISS – Open-source, high-performance similarity search
- Pinecone – Fully managed, scalable vector database
- Chroma – Lightweight and developer-friendly
Choosing the right vector database depends on scale, latency requirements, and deployment environment.
Embeddings & Similarity Search
Embeddings encode semantic meaning into vectors. Similarity search uses distance metrics such as cosine similarity or Euclidean distance to find relevant documents.
Advanced retrieval techniques include:
- Hybrid search (keyword + vector search)
- Re-ranking using LLMs
- Metadata-based filtering
These techniques improve precision and relevance.
RAG Pipeline Workflow
The RAG pipeline follows a structured workflow:
- User submits a query
- Query is converted to an embedding
- Relevant documents are retrieved
- Context is injected into the prompt
- LLM generates a grounded response
This workflow ensures that responses are based on actual data rather than assumptions.
RAG with LangChain
LangChain simplifies RAG implementation by providing:
- Built-in retrievers
- Vector store integrations
- Prompt templates for context injection
- Memory and agent support
This allows developers to build production-ready RAG systems with minimal effort.
Advanced RAG Patterns
Modern RAG systems use advanced patterns such as:
- Multi-query retrieval
- Hierarchical retrieval
- Agent-driven retrieval
- Self-refining retrieval loops
These patterns improve accuracy for complex queries.
RAG Use Cases
1. Enterprise Knowledge Assistants
Employees can query internal documents, policies, and reports using natural language.
2. Customer Support Automation
AI agents provide accurate answers based on product manuals and FAQs.
3. Legal and Compliance Systems
RAG ensures responses are grounded in official documents and regulations.
4. Healthcare Information Systems
Doctors and staff retrieve information from medical guidelines and research.
5. Technical Documentation Search
Developers query codebases, APIs, and system documentation efficiently.
RAG vs Fine-Tuning
Fine-tuning modifies model weights and is expensive and static. RAG provides:
- Real-time updates
- Lower operational cost
- Better transparency
- Faster iteration
For most enterprise use cases, RAG is the preferred approach.
Challenges in RAG Systems
Common challenges include:
- Poor document chunking
- Retrieval latency
- Irrelevant context injection
- Data quality issues
These challenges are addressed through retrieval optimization, re-ranking, and monitoring.
Security and Access Control in RAG
RAG systems must enforce:
- Role-based access control
- Data masking
- Audit logging
This ensures secure handling of sensitive information.
Future of RAG in AI Agents
RAG is evolving with:
- Multimodal retrieval
- Real-time data streaming
- Autonomous retrieval agents
- Self-learning knowledge pipelines
These advancements will further enhance AI agent reliability.
Summary
Retrieval-Augmented Generation is a cornerstone of modern AI Agent Architecture. By grounding LLM responses in real data, RAG enables accurate, trustworthy, and scalable AI systems. When combined with LangChain and LLMs, RAG transforms AI agents into powerful knowledge-driven solutions suitable for enterprise deployment.

